
Today I ran a side-by-side experiment on the same problem across two projects and spent 3 hours on it. The conclusion was clear:
In the business environment of mobile security and gray-market app testing, chasing full automation coverage can take far more time than doing the clicks by hand.
I spent enough time on this that I want to record how this should be designed from an engineering point of view when a process needs to run stably for a long time inside a private tool app.
Full-AI Automation Attempts: Open-AutoGLM and MobileAgent-v3
Once the goal shifts from can run to close to 100% stable, the difference becomes obvious:
Open-AutoGLMis a single loop: screenshot -> action -> execute.- MobileAgent-v3 adds post-action reflection and failure branching, and repeated failures can trigger replanning.
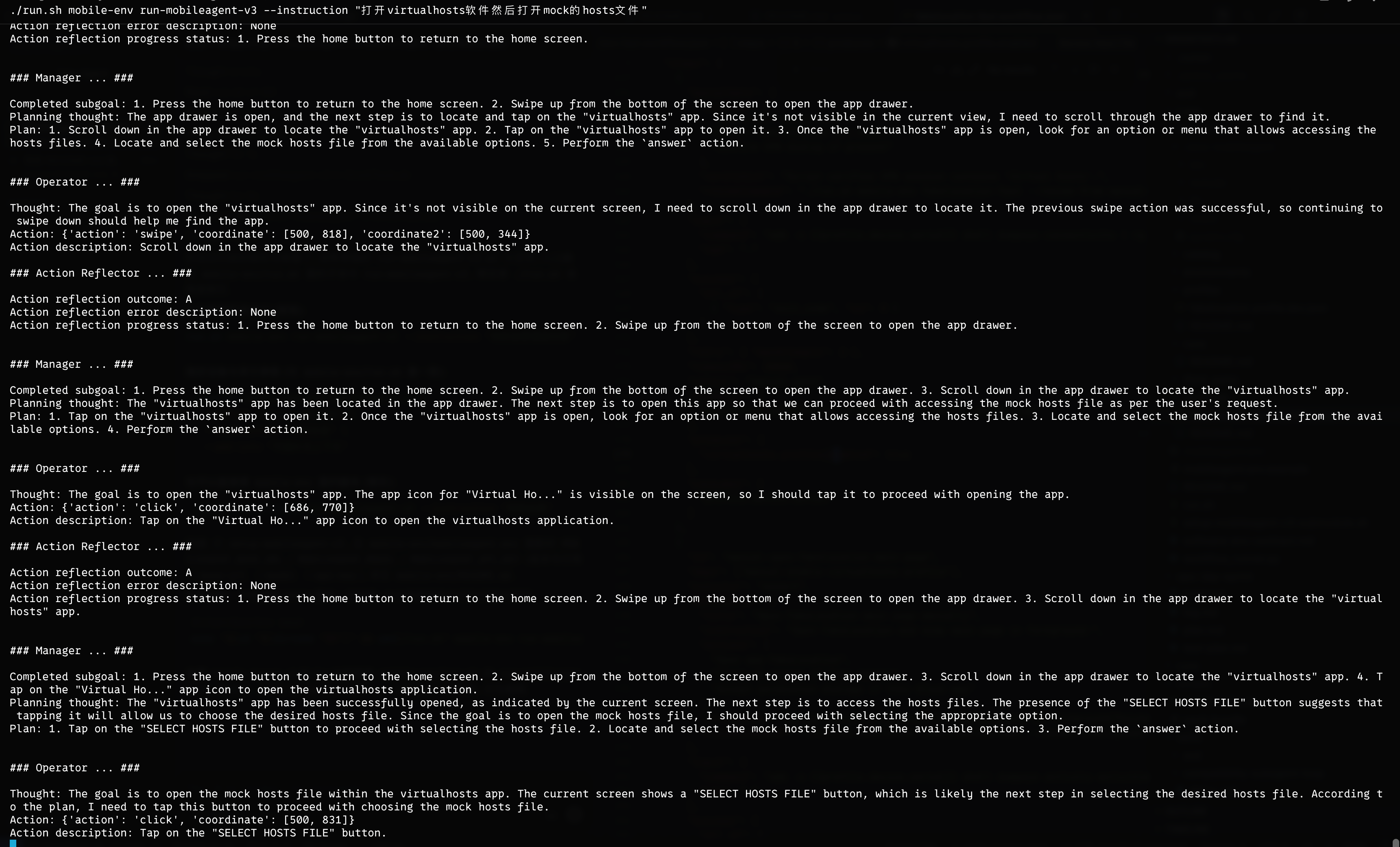
Pretty impressive. It feels like it grew a brain.
I turned one gray-market test flow into a workflow file similar to GitHub Workflow and even gave screenshots to the AI for context, hoping to lock it down once and trust it every time.
But MobileAgent-v3 was very slow at post-action verification and failure branching. A single judgment took about 10 seconds, which meant the app could ask for root permission and the 10-second countdown would expire before the agent reacted. Then the flow had to roll back and start over. A setup that depends on server-side judgment is really too slow. One full round took 10 minutes. I was getting anxious next to it, and in the end I granted root, the device rebooted because of a device issue, and everything had to start again.
That was awkward.
Beyond that, gray-market environments usually share three traits:
- They are private apps with a lot of startup mapping and permission pre-processing.
- UI disturbance is frequent: pop-ups, ads, network state changes, and even device reboots can break the chain.
- The regression chain is long, and one complete run can easily exceed 15 minutes.
For the same chain, the critical click may only take a few seconds if a human does it.
The more you push for end-to-end full automation, the more time you may waste in the least stable part.
So the metric can be split out from automation coverage into:
- Time per successful run
- Recovery cost after failure
Back to Scripts and Humans
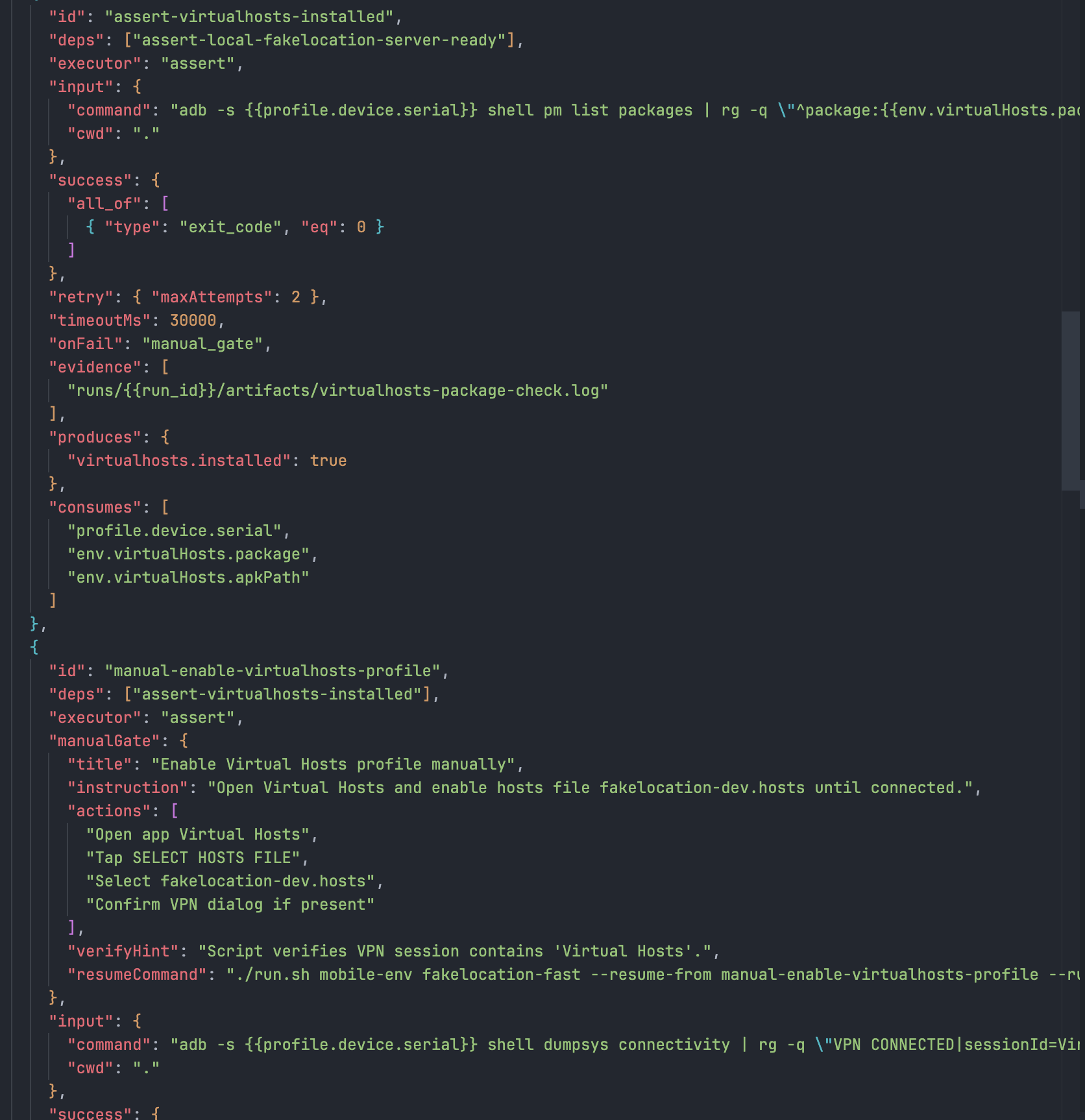
For the Fake Location chain, I changed the flow to stable segments automated + script prompts x human actions.
- The machine handles stable steps: root, install, server, health check.
- A human handles high-variance steps: critical taps, temporary pop-up handling, confirmation of file selection paths.
- After the human action, the script must immediately return to assertions. No black box is allowed to keep running.
I also kept the GitHub Workflow-like approach, but turned the protocol into a verifiable contract instead of documentation:
- Use JSON Schema for the
request/candidate/trace/verificationfields. - Provide matching example JSON.
- Run the validator and workspace validation scripts on every change.
The Core Point
The core of automation is not to replace humans. It is to script what is deterministic as much as possible, and to find determinism inside what is not.
If something really is uncertain, do not force it. Separate the uncertainty and use verifiable mechanisms to keep the cost of each layer as low as possible.
Oh, and I also fixed a BUG along the way.
I did not expect the PR to merge so quickly, and the homepage even got a small icon. That was a nice surprise.