
今天把同个问题在两个项目里做了对照实验, 花了 3h 时间, 得到一个结论:
在移动安全黑灰产测试的业务环境, 追求 全自动覆盖率 会花费比人手点多得多的时间
花了这么多时间, 我得记录一下, 当要在私有工具 App 上长期稳定执行流程时, 工程上该怎么设计.
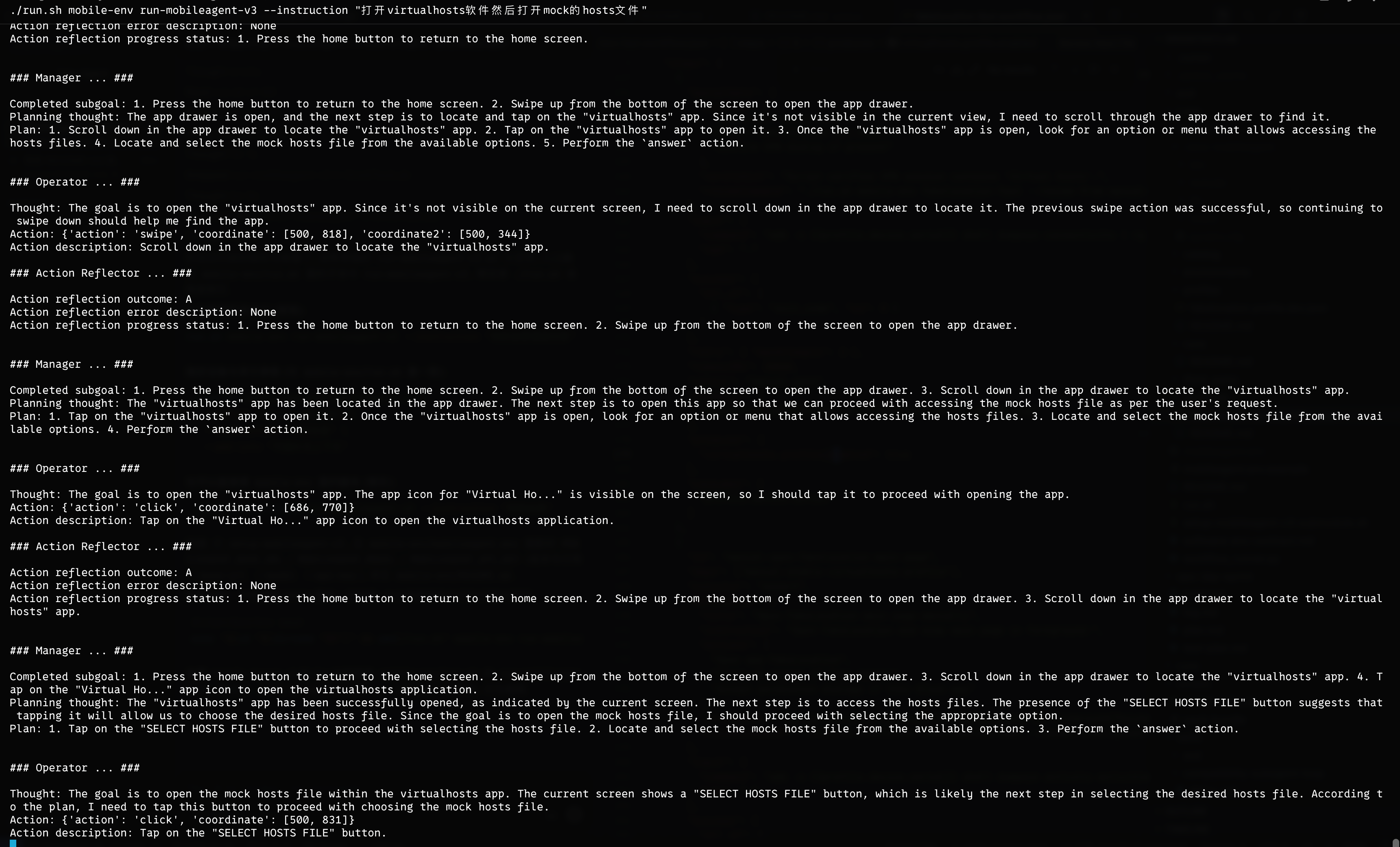
全 AI 自动化尝试: Open-AutoGLM 和 MobileAgent-v3 尝试
但当目标从 能跑 变成 接近 100% 稳定, 差异会出现:
Open-AutoGLM是单环路: 截图 -> 动作 -> 执行.- MobileAgent-v3 多了动作后反射与失败分流机制, 连续失败可触发重新规划.
挺厉害的, 感觉长脑子了.
我将某个黑灰产测试的流程, 固定为类似 Github Workflow 的流程文件, 甚至截图给到 AI 辅助理解, 以期一次固定, 次次放心.
但 MobileAgent-v3 的动作后验证和失败分流很慢, 一次判断居然需要 10s 左右, 以至于这个黑灰产 App 问我要 root 权限 10s 倒计时一过就过了, 然后流程需要回滚, 需要从头再来 (这种依赖服务端判断的方案真的是太慢了), 一轮下来, 跑通用了 10min, 我在旁边急急急, 最后给了 root 权限, 因为设备问题, 重启了, 一切又重来.
尬住.
除此之外, 对灰黑产环境进行复现, 往往有 3 个共性:
- 私有 app, 启动映射和权限前置处理较多.
- UI 扰动频繁, 弹窗, 广告, 网络态变化, 甚至导致设备重启都会打断链路.
- 回归链路长, 一次完整执行可能超过 15 分钟.
而同一条链路里, 关键点击如果交给人做, 可能只需要几秒.
越追求端到端全自动, 越可能在最不稳定的段落浪费最多时间.
所以指标可以从 自动化覆盖率 拆分为:
- 单位成功耗时
- 失败后恢复成本
回到脚本和人工
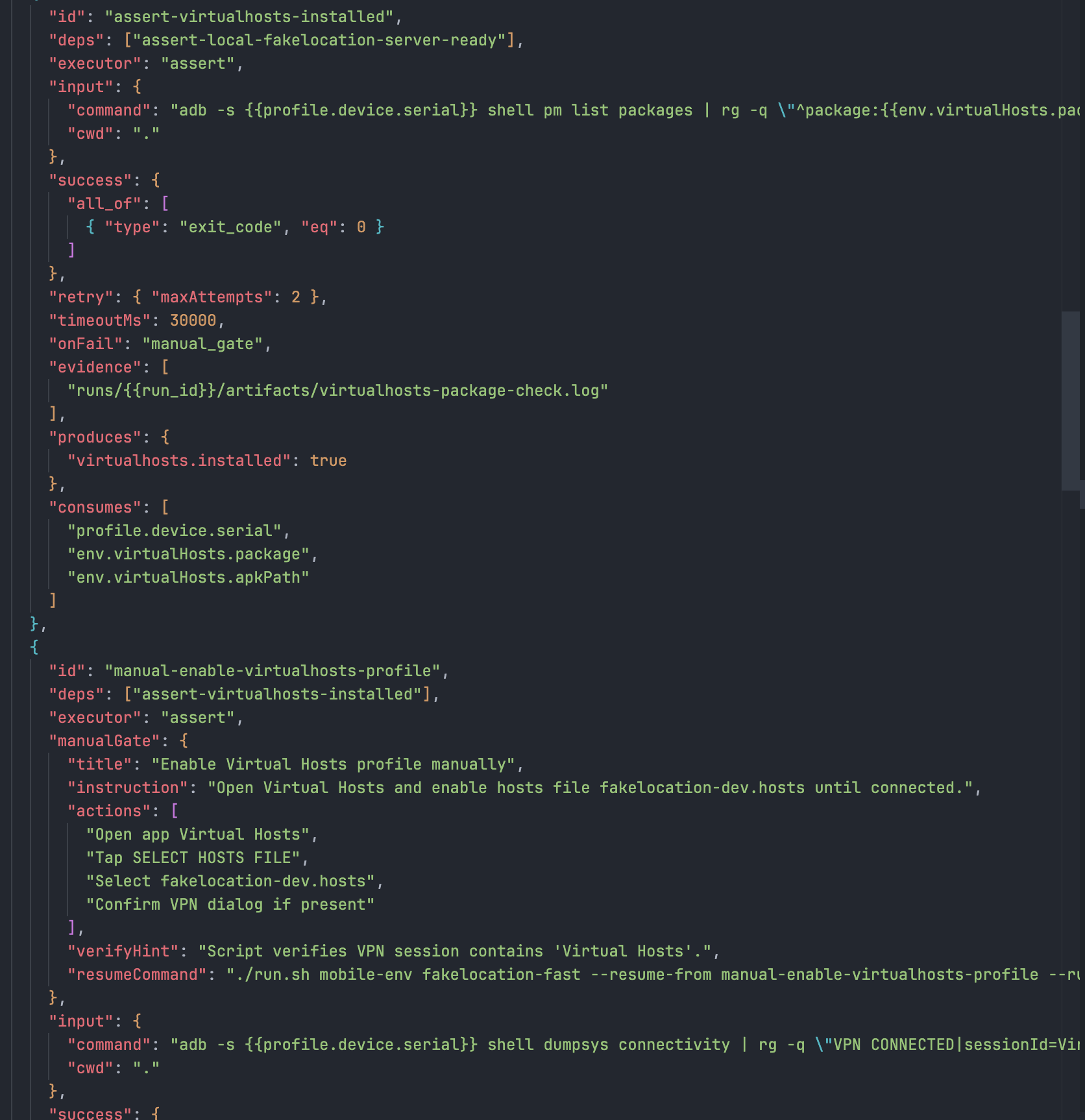
在 Fake Location 链路里, 我把流程改成 稳定段自动化 + 脚本提示x人工动作.
- 机器负责稳定步骤: root, install, server, healthcheck.
- 人负责高波动步骤: 关键点击, 临时弹窗处理, 文件选择路径确认.
- 人工动作后, 必须立刻回到脚本断言, 不允许黑盒继续跑.
除此之外, 仍然使用类 Github Workflow 的方案, 把协议做成可校验契约, 而不是文档描述
- 用 JSON Schema 写 request/candidate/trace/verification 字段.
- 配套 example JSON.
- 每次改动都跑 validator 与 workspace 校验脚本.
本质
自动化的核心不是替代人, 而是尽可能把确定性的东西脚本化, 不确定的东西寻找其确定性.
实在不确定咱也别犟, 把不确定性分离, 用可验证机制把每层的成本压到最低.
哦对了, 顺手修了个 BUG
没想到 pr 提上去没一会就合并了, 主页还多了个小图标, 蛮开心的.